

DifyでAIエージェントを作成してみた(リサーチエージェント編)【トゥモロー・ネット 技術ブログ】

ローカルAIエージェントにWEB検索を組み合わせると何ができるのか?
WEB検索を組み合わせることで、最新情報を活用したAIエージェントを実現できます。
AIエージェントの中核となるLLMは、学習時点までの情報をもとに回答を生成するため、それ以降の最新情報については把握していません。よって、学習データに含まれない新しい情報への対応には限界があります。
特にローカルLLMの場合は、運用中のモデルを頻繁に入れ替えることが難しく、信頼性が確認できたモデルを長期間利用するケースも少なくありません。そのため、扱える情報が古くなりやすい傾向があります。
そこでWEB検索によって最新情報を取得することで、ローカルLLMでも新しい情報を踏まえた回答が可能になります。
セキュリティを重視してローカルLLMを選択する企業は多い一方で、すべてを閉域環境で運用する必要があるとは限りません。クラウドAIのように社内データを外部へ送信するのではなく、WEB検索による情報取得のみを許容できるのであれば、ローカルLLMとWEB検索の組み合わせは有力な選択肢となるでしょう。
はじめに
生成AI/大規模言語モデル/LLM/RAGといった言葉が注目を集める昨今、当社ではオンプレミスAI基盤の構築にも力を入れています。
これまで10年以上にわたりサーバーやGPUの販売・保守を手掛けてきた経験を活かし、物理レイヤーに加え、ミドルウェアやソフトウェア領域についても取り組みを広げています。
このブログでは、オンプレミスサーバー上にローカルLLMとDifyを構築し、Web検索ロジックを組み込んだAIエージェントの作成手順をご紹介します。
過去には同様の構成でローカルRAGを構築した事例も紹介していますので、あわせてご参照ください。
ローカルLLMとRAGを構築してみた【ローカルAI基盤】
https://www.tomorrow-net.co.jp/topic/topic-blog-20250717/
今回やりたいこと
・オンプレミスGPUサーバーにローカルLLMとDifyを構築する。
・Difyを使用してリサーチエージェントを開発する。
※忙しい方のために、今回作成したものはこちらです。
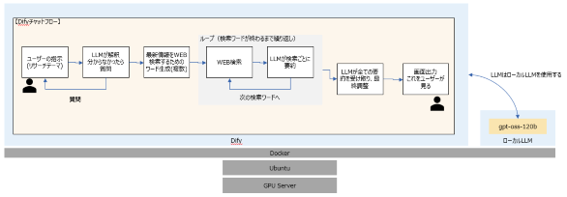
AIエージェントがユーザーの指示に応じて自律的に検索ワードを作成し、WEB検索を実行し、検索した結果を要約し、分かりやすい文章でユーザーに返しています。
システム構成と設計
【HW】
Supermicro GPU Server
NVIDIA H100 80GB x2
【SW】
OS:Ubuntu 24.04
コンテナエンジン:Docker 29.3.0
ローカルLLM:gpt-oss-120b
LLM実行エンジン:vLLM
AIプラットフォーム:Dify 1.13.3
WEB検索:Tavily Search(Difyプラグイン)
その他:NVIDIA GPU Driver、NVIDIA Container Toolkit
【AIエージェント設計】
AIエージェントはユーザーの要求に従って適切なWEB検索を自律的に行い、調べた結果を分かりやすく返すように設計します。
ユーザーの指示が曖昧な場合は聞き返すようにします。
WEB検索は一回で終わらせず、必ず複数個の検索ワードを生成して複数回検索するようにします。
最後に要約してユーザーに提示します。
ローカルLLMとDifyのデプロイ
OSとNVIDIA Driver、NVIDIA Container Toolkitはインストール済みだったのでスキップします。
・Dockerインストール
こちらを参考にインストールしました。
https://docs.docker.com/engine/install/ubuntu/
・ローカルLLMとvLLMをデプロイ
gpt-oss-120bをコンテナにデプロイします。
gpt-oss-120bはこちらのモデル。
https://huggingface.co/openai/gpt-oss-120b
事前のサイジングで4bit量子化モデルならH100 80GBに収まる想定でしたが、KVキャッシュを含めるとギリギリ入らず、H100 2枚の贅沢な構成になりました。
vLLLMのパラメーターに”–tensor-parallel-size 2”を追加し、2枚のテンソル並列にします。
最終的に以下のようになりました。gpt-oss-120bのモデルはあらかじめホストの/srv/vllm/modelsにダウンロードしてあります。
<docker-compose-gptoss120b.yml>
services:
vllm-gpt-oss-120b:
image: vllm/vllm-openai:v0.19.0-cu130-ubuntu2404
container_name: vllm-gpt-oss-120b
restart: unless-stopped
ports:
– “31001:8000”
ipc: host
volumes:
– /srv/vllm/models:/root/.cache/huggingface
# GPU 0番と1番を割り当てる設定
deploy:
resources:
reservations:
devices:
– driver: nvidia
device_ids: [‘0’, ‘1’]
capabilities: [gpu]
# コンテナ起動時の引数
command: >
openai/gpt-oss-120b
–tensor-parallel-size 2
–gpu-memory-utilization 0.80
–trust-remote-code
・Difyをデプロイ
Difyもコンテナにデプロイします。
こちらを参考にデプロイしました。
https://docs.dify.ai/en/self-host/quick-start/docker-compose
DifyはDockerエンジンとdocker composeが使える環境であれば簡単にデプロイできます。
初期設定が少し難しく、経験が無いと何を変えたらいいか分かりません。ここは弊社のナレッジが生かせる部分です。
・DifyとローカルLLMの接続
Difyがうまくデプロイ出来たのでWEBポータルに入れるようになりました。
ログインしてローカルLLMに接続します。
設定のモデルプロバイダーでgpt-oss-120bに接続しました。
これでDifyからLLMが使えるようになります。
この時点で、簡単なチャットボット程度であればすぐに利用可能です。
今回はAIエージェントなのでここからが本番です。
AIエージェントの作成
いよいよAIエージェントを実装していきます。
Difyは直感的なUIなのですぐ作れそうですが、作成に入る前にやりたいことの明確化が必要です。今回は以下のように書き出しました。
【トレンドリサーチエージェント】
・ユーザー:「○○のトレンドを調査したい」の様に入力
・LLM:ユーザーの期待に応えるにあたり、追加で何をユーザーに確認すべきか生成
・Dify:質問をユーザーに表示
・ユーザー:希望することを回答
・LLM:最初の入力と2番目の入力を総合して検索ワードを複数個生成
・Dify:WEB検索(Tavily Search)によりランキングやトレンドを取得
・LLM:集めた情報を集約、要約してまとめる
・Dify:結果を出力
これをDifyの“チャットフロー”に落とし込んでいきます。
以下の様になったのでピックアップして解説します。
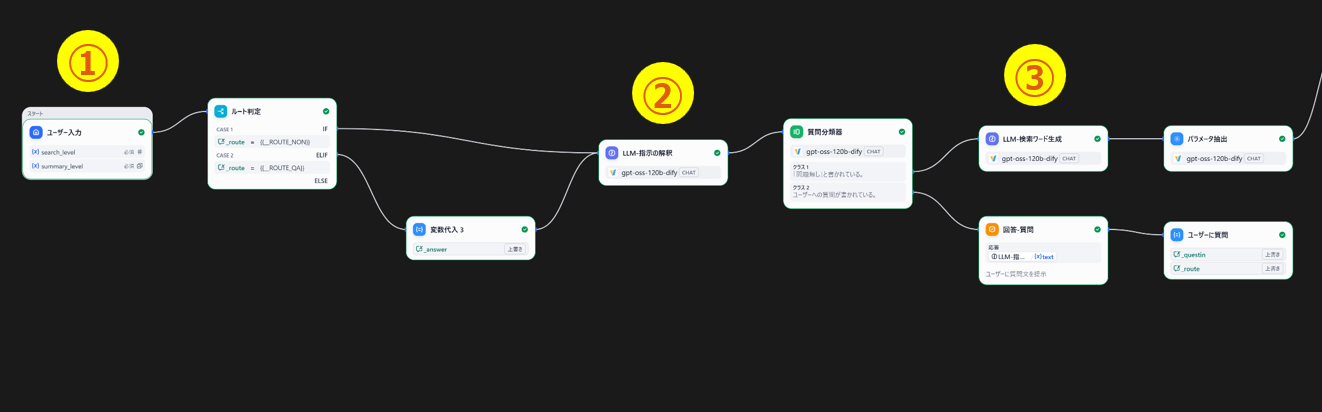
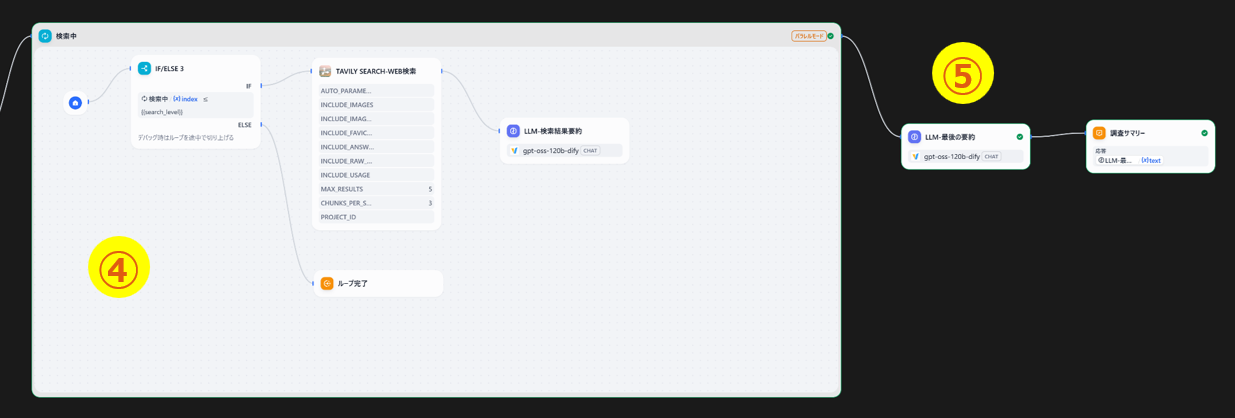
① 入力フォームの設定
検索の深さや要約レベルを設定できるようにし、チャットの入力例を提示するようにしました。
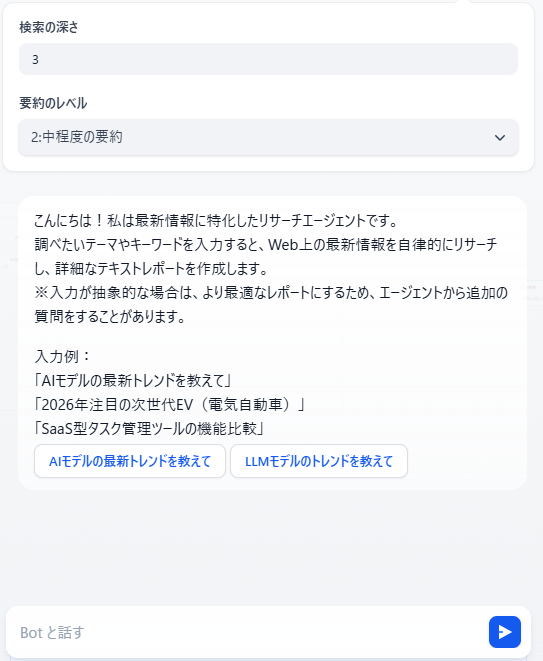
②指示を解釈(LLM)
ユーザーが入力した指示を解釈し、このままリサーチに進んでいいか判断させます。進めない場合、ユーザーへの追加質問を生成します。
③検索ワードの生成(LLM)
ユーザーが入力した指示と追加質問の回答(あれば)から検索ワードを複数生成します。
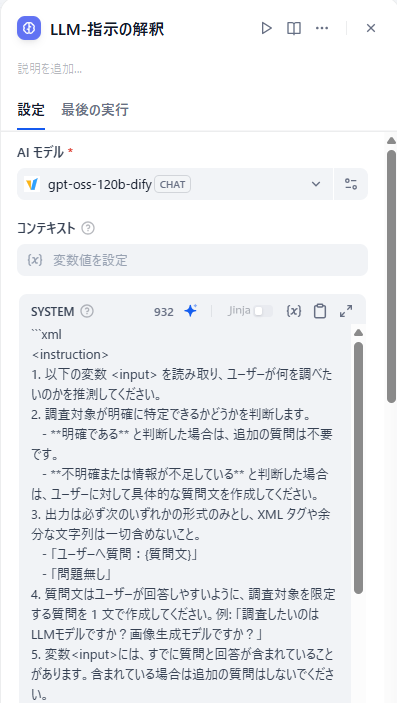
④WEB検索ループ
生成された検索ワードで順にWEB検索していきます。WEB検索にはTavily Searchのプラグインを利用しました。
検索ワードが大量に生成できた場合でも、入力フォームに設定された“検索の深さ”を上限として検索を切り上げるようにしました。
取得するテキストが多くなりすぎると最後のまとめでLLMのトークン上限を超える恐れがあるため、検索の都度要約を実施しています。
さらにディープリサーチしたい場合、検索結果からURLを取得し、検索ワードを作成することで掘り下げていけそうです。
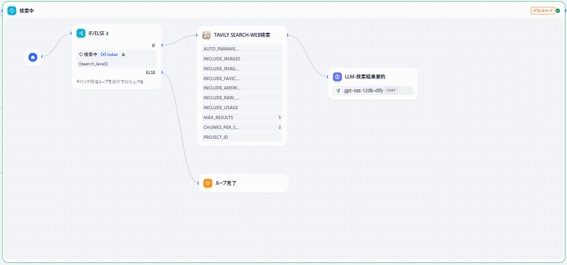
⑤最後の要約(LLM)
複数回にわたってWEB検索された結果をユーザーに分かりやすいようにまとめます。
要約のレベルは最初の入力時に設定できます。
実際に動かした結果はこうなりました。
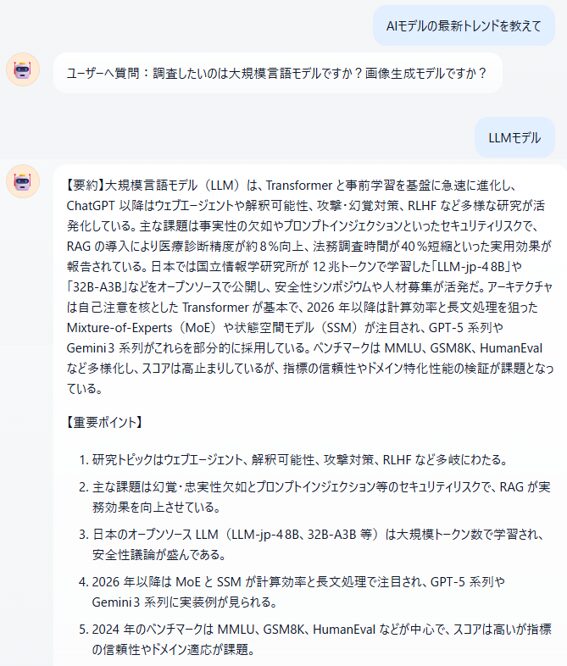
LLM‑jp‑4 8Bは2026年4月に公開された日本のオープンソースLLMです。
今回使用しているgpt-oss-120bは2025年に公開されたモデルのためLLM‑jp‑4 8Bのことを学習しているはずがなく、うまくWEB検索をデータソースとして回答できたことが分かります。
内容をクラウドのgeminiに評価させたところ、最新情報が反映されたリサーチとしてほぼ正しいとの評価をもらうことができました。
これでAIエージェントの作成も完了です。
まとめ
今回はオンプレミスサーバーにローカルLLMとDifyを構築し、チャットフローによるAIエージェントの実装まで行ってみました。
ローカルLLMとDifyの組み合わせは、クラウドLLMを利用しない社内データ活用として非常に注目されています。社内データをDifyのデータベースに保存し、それをLLMが利用する“RAG”を構築するのですが、今回ご紹介したチャットフローやワークフローを利用することでWEB検索に限らず様々な応用が効くようになります。
高度なフローには多少のプログラミング能力やアルゴリズムへの理解を求められるものの、簡単なものであれば一般職の方でもAIアプリを作れるのもDifyの良いところです。
簡単なチャットボットやAIアプリ開発からスタートし、頑張り次第でフローやプラグインを駆使した本格的な業務AIエージェントまで、オンプレミスでのデータ活用の幅は広がっていくことでしょう。
トゥモロー・ネットでは今回ご紹介したローカルLLM、Difyのほか、オーダーメイドのAI基盤構築などのGPUサーバー導入支援も行っています。
ご興味がある方は、ぜひお問い合わせください。
お問合せ先

関連ページ
ローカルLLMとは?クラウドAIとの違い・必要なサーバーのスペックを解説
ローカルLLMとRAGを構築してみた【ローカルAI基盤】
人事担当が社内チャットボットの構築を手伝ってみた
この記事を書いた人

株式会社トゥモロー・ネット
トゥモロー・ネットは、AI基盤向けインフラの設計・構築・運用を支援しています。GPUサーバーの導入実績1,200台以上、 保守実績66,000台以上の知見をもとに、システム全体の性能や運用性を考慮した提案を行っています。
NVIDIAの最上位パートナープログラム「NVIDIA Elite Partner」に認定され、Supermicro正規一次代理店として10年以上にわたりAIインフラ分野を支援しています。
本サイトのコンテンツは、NVIDIA認定技術者および専門エンジニアを含む技術チームが執筆・監修しています。