

ローカルLLMとRAGを構築してみた【ローカルAI基盤】 【トゥモロー・ネット 技術ブログ】
生成AI、特にLLM(大規模言語モデル)がもてはやされている昨今、弊社でもGPUやAI導入のご相談やお問い合わせをいただきます。
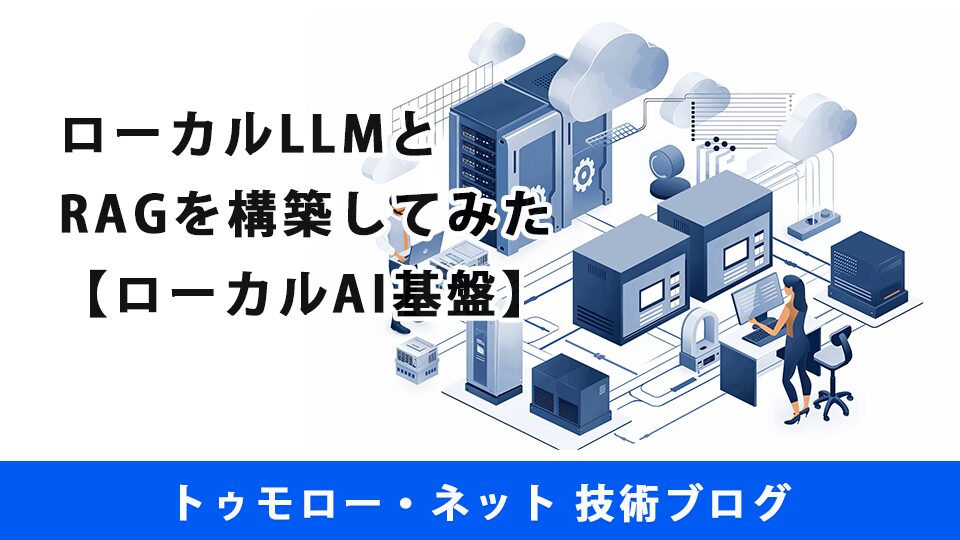
特にご相談が多いのがローカルLLMの構築です。ChatGPTやCopilot、GeminiのようなクラウドのAIの利用が禁止されている、またはAIに聞けることに制限が設けられている企業様は多く、その制限を回避するためにオンプレ(クラウドではなく企業のネットワーク内に設置されたサーバー)のGPUサーバーにローカルLLMを構築したいというのが理由です。
しかし、オンプレサーバーにローカルLLMを構築するだけではAIの回答精度は業務レベルに達していないことも少なくありません。 GPUサーバーのスペックの問題ではなく、そもそもAIが企業固有のデータを学習していないためです。
このブログでは、その回答精度の不十分さを補うためにRAG(Retrieval-Augmented Generation:検索拡張生成)の環境を構築し、LLMの反応がどのように変わるのかを解説します。
目次
ローカルLLMとRAGとは?
ローカルLLMというのは、クラウドではなくオンプレに構築されているLLMのことです。
自社でGPUサーバーを調達し、そのサーバーにLLMを構築して動作させます。こうすることで、クラウドとの通信が必要なく、例えばLLMへの質問文に社内の機密情報や非公開情報を含んでいても、情報がインターネットに公開されてしまう心配がありません。
機密性の高い情報を扱う企業に向いている方式です。
もう一つのRAGとは、AIが学習していない情報を補完する仕組みです。AIは通常、インターネットに公開されている技術情報、歴史、ニュースなど、非常に多くのオープンデータを学習しています。
しかし公開されていない情報は学べないため、各企業の機密情報や、社内向けにしか公開していないマニュアル、就業規則、規定などの情報は保有していません 。ですので、仮に特定の企業の社内向け情報について質問したとしても「一般的には○○○」のような一般論しか 返ってきません。
その対策として非公開情報を社内のデータベースに持っておき、LLMに渡す仕組みを構築することで、非公開情報でも正しい回答をくれるようになります。この仕組みがRAGです。

今回やりたいこと
ローカルLLMとRAGを構築し、非公開情報をLLMに正しく回答してもらうことを想定し、動作時にインターネットに接続が必要ない環境を構築します。
※本当はGPUサーバーを使いたかったのですが空いていないので自分のノートPCを使用します。GPUが無いので計算リソースが貧弱な上、UbuntuはHyper-VのVMに構築してあるので余計きつかった…。
ベクトルDBにマニュアルを登録し、マニュアルと齟齬が無い回答をLLMが返してくれれば成功です。
また、VMにはあらかじめOSとDocker、Docker Composeまではインストールしてあるので、上流のコンテナから作成していきます。
ローカルLLM構築(ollama)
ローカルLLMにはollama(https://ollama.com/)というライブラリーを使用します。
Ollamaは扱えるAIモデルが限られますが、手軽にLLMを動かせるのでよく使っています。
Ollama用のコンテナを作るところからスタートです。
・軽量なDockerイメージを使用してコンテナを作成。-pはポートフォワーディング設定で、ollamaのポートを空けるために指定した
(今回はイメージがダウンロード済みだったが、本来はイメージダウンロードが走る)
docker run -it –name ollama-run -p 11434:11434 ubuntu:24.04

・ollamaをインストール
apt update
apt install curl
curl -fsSL https://ollama.com/install.sh | sh

・ollama serveをバックグラウンドで起動
nohup ollama serve &
・AIモデルをpullして実行。”phi3:3.8b”はMicrosoft製の軽量LLM
ollama pull phi3:3.8b
ollama run phi3:3.8b

LLM(phi3:3.8b)との対話モードに入りました。たった数ステップのコマンドでここまで来られるのがollamaのいいところです。

でも精度はイマイチ(東京は1943年まで江戸という回答が出力されてしまっていますね )。
これはphi3:3.8bがかなり軽量なモデルで、かつ日本語で質問したため。英語だともう少しマシになります。

とりあえずローカルLLMが動きました。
精度は不満がありますが 、すでにPCが悲鳴を上げているためphi3:3.8bで進めます。
GPUサーバーであればもっとパラメーター数の大きなモデルを使用することができるため、精度が劇的に上がります。
このあとDifyと接続(Dify側からollamaにAPIアクセス)するためひと手間加えます。
ollama serveへのアクセスはローカルからは可能ですが、初期状態では別のIPアドレスからのAPI接続は制限されています。
そのため、以下の 手順で制限を解除し、Difyからのアクセスを受け付けるようにします。
・ollama用の環境変数を~/.bashrcに書き込み
echo ‘export OLLAMA_HOST=0.0.0.0’ >> ~/.bashrc
echo ‘export OLLAMA_ORIGINS=*’ >> ~/.bashrc
・あらためてollama serveを起動
nohup ollama serve &
これでollamaコンテナでの作業は完了です。
Ollama serveがLLMを実行できる状態で待機しているので、そこにDifyから接続してチャットの質問文を投げ込む予定です。

プラットフォームの構築(Dify)
次はDifyの構築です。
DifyはオープンソースのAIプラットフォームで、インストールするだけでLLMとのチャットUIを提供してくれたり、API経由でollamaを始め様々なAIサービスと接続できます 。RAGの機能も備えており、今回のテーマにはうってつけでした。
DifyはDocker Composeというコンテナをデプロイする仕組みに対応しているため、それを使用してデプロイしていきます。
まずはDifyのGitHubを確認してみましょう。ここにDifyのリポジトリーがあります。
この後の手順では、このリポジトリーをローカルにダウンロードし、デプロイを実施します。
https://github.com/langgenius/dify
・GitHubからDifyリポジトリーをダウンロード
git clone https://github.com/langgenius/dify.git

lsを実行するとdifyディレクトリーが作成されています。
・dify/dockerに移動

ここにdocker-compose.yamlがありました。
・サンプルの環境設定ファイルをリネーム(今回は編集せずそのまま使います)
cp .env.example .env
・いよいよDocker ComposeでDifyコンテナをデプロイ
docker-compose up -d
Dockerコンテナのイメージがダウンロードされていく

すべてのコンテナのデプロイと起動に成功しました。
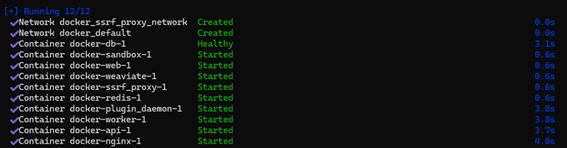
Difyのデプロイは完了です。
Docker Composeツールさえインストールしておけばこちらも数ステップで完了しました。
DifyからローカルLLMへの接続と、RAG構築
ここまででローカルLLM(ollama)とDifyが構築できました。後はDifyのWEBポータルから作業していきます。
・手元のWindows PCからDifyポータルへアクセスし、管理者アカウントを作成します。
80番ポートが空いているので http:// でアクセスできます。
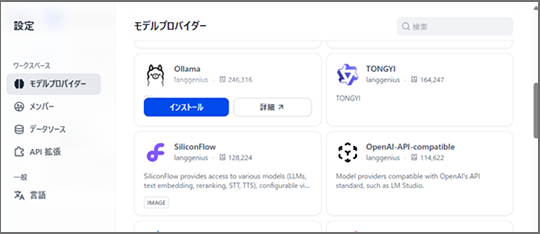
・メニューからモデルプロバイダーの設定に進み、ollamaと接続します。
・AIモデルのphi3:3.8bを指定し、ollamaコンテナへのIPアドレスとポートを設定
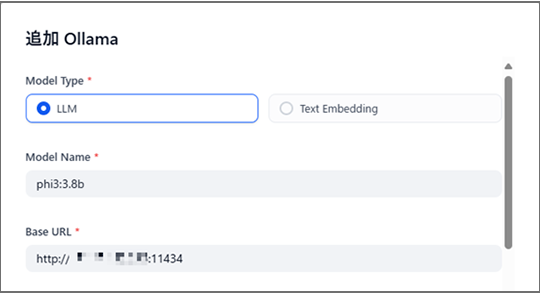
これでDifyとLLMが接続されました。
続いてRAGのためにマニュアルを投入します。
・ナレッジに進み、PDFをD&Dで投入。
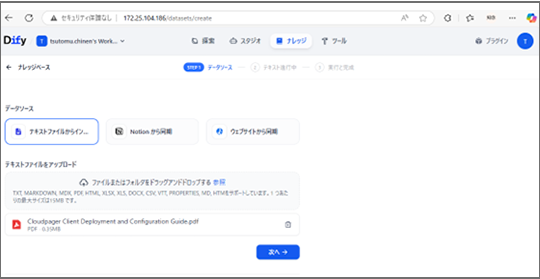
今回はCloudpagerという製品の英語マニュアルを登録しました。
(実は日本語マニュアルも試したのですが精度が低すぎたため、泣く泣く英語マニュアルとなりました。)
最後にphi3:3.8bを使用したAIチャットボットの作成とRAG設定を行います。
・チャットボットの画面に進み、右上にphi3:3.8bを設定。以下のスクリーンショットではRAGを使用せずにAIに質問を投げ、回答をもらっています。
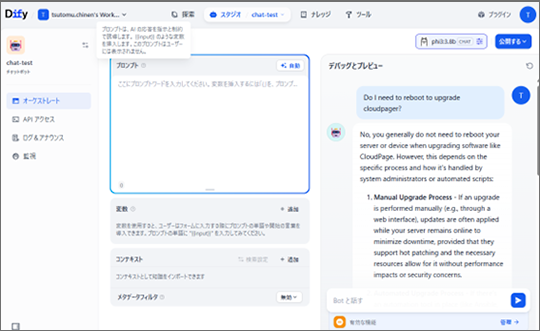
【質問】Do I neet to reboot to upgrade cloudpager?( cloudpager をアップグレードするには再起動が必要ですか?)
AIの回答は、「デバイスの再起動は通常必要ない」というものでした。この回答は間違いです。Cloudpagerをアップグレードする際には、必ずデバイスの再起動が必要です。
AIはごく一般的なソフトウェアについての回答をしているだけで、Cloudpagerという製品について正しい回答をくれませんでした。
・次にRAGを使用する設定で同じ質問をします。左下当たりの“コンテキスト”にCloudpagerのナレッジを設定しました。
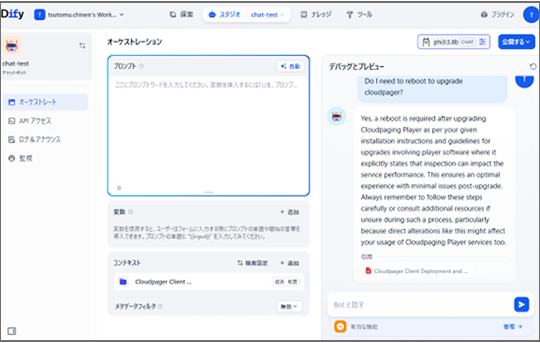
【質問】Do I neet to reboot to upgrade cloudpager?( cloudpager をアップグレードするには再起動が必要ですか?)
AIの回答は、「デバイスの再起動が必要」というものでした。かつマニュアルに明記されているということ、マニュアルの該当箇所の引用も添付してくれています。
これでローカルLLMを使用したRAGの構築が完了しました。
まとめ
GPUを搭載しないノートPCでの検証でしたが、無事ローカルLLMとRAGを構築し、マニュアルの情報をもとにAIが回答する動作を実現できました。
このような環境を構築することで、機密データをインターネットに送信することなく企業に合ったLLMを構築することができます。
ただ、今回はPCのパワー不足でAIモデルが貧弱になってしまい、 日本語マニュアル・日本語での問い合わせが検証できないという課題が残りました。
本来はGPUサーバーに構築するものなので、3.8bではなく70b、405bなどのより大きなAIモデルを使用します。そうすることで 精度も段違いに向上し 、日本語でも問題無くコミュニケーションできるようになってきます。
トゥモロー・ネットではAI基盤の構築の他、GPUやサーバーの仕入れ、お客様の要件をヒアリングしたスペックのサイジングも行っています。
興味があればぜひお問い合わせください。
お問合せ先
関連記事はこちら
ディープラーニングに最適なGPUの選び方とは?おすすめのモデルも解説
LLMとGPUの関係とは?LLMに必要なGPUのスペックも解説
人事担当が社内チャットボットの構築を手伝ってみた
この記事を書いた人

株式会社トゥモロー・ネット
トゥモロー・ネットは「ITをもとに楽しい未来へつなごう」という経営理念のもと、感動や喜びのある、より良い社会へと導く企業を目指し、最先端のテクノロジーとサステナブルなインフラを提供しています。設立以来培ってきたハードウェア・ソフトウェア製造・販売、運用、保守などインフラに関わる豊富な実績と近年注力するAIサービスのコンサルティング、開発、運用、サポートにより、国内システムインテグレーション市場においてユニークなポジションを確立しています。
インフラからAIサービスまで包括的に提供することで、システム全体の柔軟性、ユーザビリティ、コストの最適化、パフォーマンス向上など、お客様の細かなニーズに沿った提案を行っています。