

今更聞けないPacemakerとCorosyncによるHAクラスタ構成【トゥモロー・ネット 技術ブログ】

アプリケーションの可用性を担保するやり方として、仮想化環境ではVMwareやProxmoxのような仮想マシン(ハイバーバイザー)によるゲストOSレベルでの可用性を担保するやり方、また、最近のコンテナ環境では、Kubernetes(k8s)によるPodレベルでの可用性を担保するようなやり方が一般化してきているかと思います。
一方で、アプリケーションの要件で、仮想化やコンテナ化に移行できないものを物理OSレベルで可用性を担保するやり方も以前から存在していました。
今回は、そのやり方の一つとして、長年、OSS(オープンソースソフトウェア)として開発が継続されているクラスタウェアであるPacemakerおよびCorosyncを利用することで物理OS環境でのクラスタ構成によるサービス保護(アプリケーションの可用性担保)について、考えてみたいと思います。
Linux OSでのHAクラスタ構成について
一般的なHigh Availability(HA)クラス構成とは、2台以上のサーバーと各サーバーとデータを共有するためのストレージ(共有ストレージ)によって構成されるシステム構成になるかと思います(参考イメージ図)。
いわゆる3Tier構成(サーバー、SAN Switch、共有ストレージ)で、サービス保護対象とするアプリケーションの動作継続に問題が発生した場合にサービス継続のために必要な制御対応を実行するソフトウェア(クラスタウェア)で構成されます。
ハードウェアを構成するポイントとしては、まず、Single Point Of Failure (SPOF, 一点障害)がないようなハードウェアの二重化(冗長化)構成し、かつ、それを利用するソフトウェア設定構成(ディスクのマルチパス設定、ディスクのRAID設定, ネットワークのbonding設定)がまずは、前提となります。
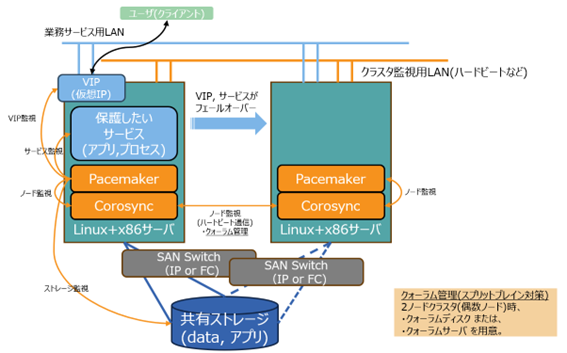
ハードウェアの冗長化構成を行った上で、HAクラスタを構成する中心的なソフトウェアが、PacemakerとCorosyncという二つのOSSソフトウェアになります。
Pacemaker:リソースの監視と制御を担当
Pacemakerは、オープンソースの高可用性(High Availability:HA)クラスタリングソフトウェアです。主にLinux環境で使用され、システムの冗長化を実現するために利用されます。
主な役割は、リソースマネージャーとして、クラスタとして提供するリソース(サービス(プロセス)、仮想IP、ファイルシステムなど)の管理やフェイルオーバー(稼働するサーバー切り替え)処理を行います。
Corosync:クラスタノード(サーバ)の死活管理
Corosyncは、オープンソースの高可用性クラスタ通信フレームワークです。主にLinux環境で使用され、クラスタ内のノード間通信を管理します。
主な役割は、クラスタを構成するノード(サーバー)間のメッセージングとクォーラム管理機能を提供します。ノードの状態を監視し、異常が発生した場合は、Pacemakerに通知することで、適切なフェイルオーバー処理を行うことを可能とします。
PacemakerとCorosyncが連携動作することで、可用性システムを構成することになります。
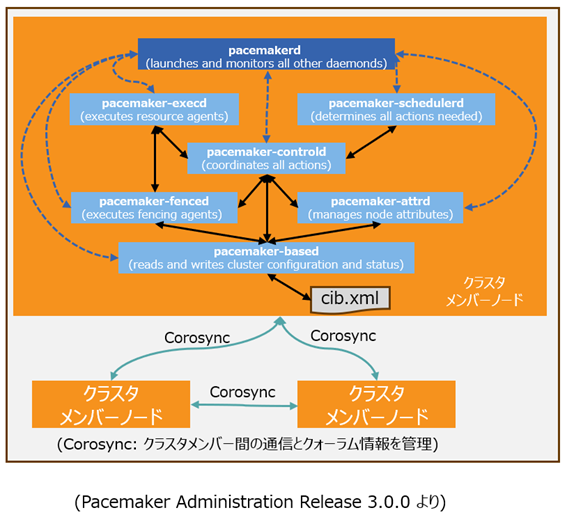
上図では、Pacemakerで動作する複数のプロセス名称とその役割を模式的に説明したものです。
(ClusterLabs, https://clusterlabs.org, Pacemaker Administrator Release 3.0.0より)
- pacemakerd: メインプロセス
他のすべてのデーモンを生成、管理 - pacemaker-based: CIBマネージャー
クラスタ情報ベース(CIB.xml)の維持管理、クラスタでの同期処理を実行 - pacemaker-attrd: 属性マネージャー
全ノードの属性変更を管理し、クラスタでの同期処理を実行 - pacemaker-schedulerd: スケジューラー
(スナップショットされた)CIB情報から期待されるクラスタ状態を達成するためのアクションを決定 - pacemaker-execd: ローカルエクゼキュータ
リソースエージェントの実行要求を処理 - pacemaker-fenced: フェンサー
ノードのフェンス要求を処理、どのノードがどのフェンスデバイスで実行すべきか決定し、必要なフェンスエージェントをコール - pacemaker-controld: コーディネーター
クラスタメンバーシップの一貫したビューを維持し、他のすべてのコンポーネントを調整
コントローラーインスタンスの1つを指定コントローラー(DC)として選出。DCプロセス(またはそのノード)が失敗した場合、新しいDCが迅速に確立されます。
DCはCIBの現在のスナップショットを取得し、それをスケジューラに渡し、エクゼキュータやフェンサーに必要なアクションを要求することで、クラスタイベントに対応します。
ここからは、PacemakerやCorosync以外で、HAクラスタ運用で重要な付加的な機能について、取り上げていきたいと思います。
クラスタ構成を支える付加機能について
クォーラム機能 ~タイブレーカ―~
クラスタでのQuorum(クォーラム)機能は、クラスタの安定性とデータ整合性を維持するための重要な仕組みです。
クォーラムは、クラスタ内のサーバー(ノード)の過半数が稼働していることを確認することで、スプリットブレインシナリオを防ぎます。スプリットブレインとは、クラスタが通信から分離された後も、各部分が別のクラスタとして機能し続けることで、同じデータの書き込みやデータの破壊または損失が発生する現象です。
適切にQuorumを設定することで、障害発生時にクラスタ全体が不要な分断やデータ不整合を回避できます。
以下は、Quorum機能をQuorumサーバーとして用意する例で示します。


フェンシング機能
Pacemakerでのクラスタ内の異常が発生したサーバーをクラスタから分離するプロセスをフェンシング(Fencing)と呼ばれます。
具体的には、STONITH(Shoot The Other Node In Head)というプロセスを使用して、異常が発生したサーバーを停止または、再起動を行うことでクラスタの可用性を維持することができます。
以下では、マルチパス設定されたデバイス構成とそれらのデバイスに対するフェンシング構成について紹介します。
マルチパスデバイス構成でのフェンシングを行うための機能とその設定
(Persistent Reservation、Reservation key設定、fence_mpath設定)
マルチパス接続されたデバイスに対するPersistent Reservation(永続予約)
Persistent Reservation とは、特定のサーバーがストレージデバイスに対して、独占的なアクセス権を持つことを保証するために利用されます。
主な目的
- データの一貫性の確保
複数のホストが同じストレージデバイスにアクセスする場合、データの一貫性を保つために予約が必要です。 - フェイルオーバーのサポート
予約を使用することで、フェイルオーバー時に他のホストがデバイスにアクセスできるようにすることができます。
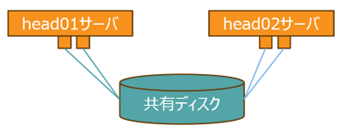
Persistent Reservationは、複数のシステムが共有ストレージデバイスにアクセスする必要がある環境(例えばクラスタシステム)で重要な機能です。(sg_persist(8))
マルチパス接続に対応した永続予約の方法について
このユーティリティは、デバイスマッパーマルチパスデバイス上のSCSI永続予約を管理するために使用されます。この機能を使用するには、/etc/multipath.confファイルにreservation_key属性を定義する必要があります。
これにより、multipathdデーモンは新しく発見されたパスや再インストールされたパスの永続予約をチェックします。mpathpersist(8)
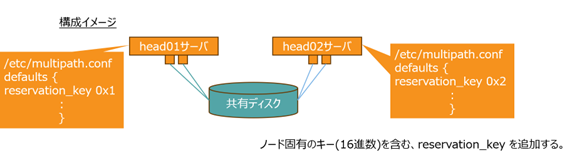
fence_mpath設定
Pacemakerにおいて、これまで述べてきた機能を使って、マルチパス設定されたデバイスへのフェンシング処理を実装した例を以下に記載します。
管理するマルチパスデバイスのリストとキー(Reservation Key)へのサーバーのマッピングを指定して、共有STONITHデバイスを設定します。Fence_mpathは、device属性でマルチパスデバイスを定義可能です。キーに対するサーバーのマップを作成するには、pcmk_host_map で指定し、pacemakerで属性設定が必要です。
例示する設定は、2台のクラスタサーバー(head01, head02)で共有されるディスクデバイス(Disk001~Disk008)をマルチパス設定で共有し、かつ、特定のサーバーが異常な状態になった場合、当該サーバーからのデバイスアクセスをブロックする設定を行ったものです。

(特記事項)
Pacemakerでのfence_mpath設定だけでは、異常となったサーバーからのデバイスアクセスをブロックすることは可能ですが、異常となったサーバー自体はそのまま起動している状態となります。
クラスタを健全な状況に移行させるためには、異常となったサーバーを強制リブートさせることが必要となります。そのためのやり方が2つ考えられます。
IPMI Fence デバイス設定
1つ目は、サーバーに搭載されているBMC/IPMIを経由したサーバーの強制リブート機能を設定するやり方です。具体的には、IPMIフェンスエージェントを追加インストールした後で、Pacemakerの設定に、IPMIデバイスのIPアドレス、ユーザー名、パスワードを指定して、フェンスデバイスを作成、フェンシングを有効にするためのクラスタプロパティを設定することで実装可能です。

ウオッチ・ドッグ・タイマー設定 ~WDT, SBT~
WDT(Watch Dog Timer)、SBD(Split Brain Detector)を追加構成
2つ目は、ウォッチ・ドッグ・タイマー(WDT)を使用してフェンシング設定する方法です。
WDTは、サーバーが応答しなくなった場合に自動的にOSを再起動することでクラスタの信頼性を向上させるために使用されます。
そのためのモジュールとして、WDT(Watch Dog Timer)、SBD(Split Brain Detector)を追加構成します。

さらに、Pacemakerではこの2つのフェンシング機能を定義することができます。フェンスレベルを設定することで、フェンスデバイスが順番に試行され、最初のフェンスデバイスが失敗した場合に次のフェンスデバイスが使用されます。
以下は、Level1とLevel2で二つのフェンスデバイスを指定した例となります。
(/var/lib/pacemaker/cib/cib.xml (pacemaker設定ファイル)より抜粋

まとめ
今回は、Linuxでのクラスタ構成についてご紹介しました。可用性を担保するには、ハードウェア構成の二重化に加え、Linux OSに様々な追加モジュールが必要なことを再認識する機会でした。
トゥモロー・ネットでは、さまざまな製品選定や構成検討から導入支援サービス、保守サポートまでご相談頂ける体制をご用意しています。是非お気軽にお問合せください。
お問合せ先
関連記事はこちら
OSNEXUS QuantaStorについて~ソフトウェア・デファインド・ストレージプラットフォームを実現~
OSNEXUS社QuantaStorスケールアップ構成(OpenZFSベース)
OSNexus社QuantaStorによるスケールアウト構成(Ceph)ファイル/ブロック/オブジェクトサービス
この記事を書いた人

株式会社トゥモロー・ネット
トゥモロー・ネットは「ITをもとに楽しい未来へつなごう」という経営理念のもと、感動や喜びのある、より良い社会へと導く企業を目指し、最先端のテクノロジーとサステナブルなインフラを提供しています。設立以来培ってきたハードウェア・ソフトウェア製造・販売、運用、保守などインフラに関わる豊富な実績と近年注力するAIサービスのコンサルティング、開発、運用、サポートにより、国内システムインテグレーション市場においてユニークなポジションを確立しています。
インフラからAIサービスまで包括的に提供することで、システム全体の柔軟性、ユーザビリティ、コストの最適化、パフォーマンス向上など、お客様の細かなニーズに沿った提案を行っています。