


NVIDIA H200とは?
生成AIとHPCのためのGPU
NVIDIA H200 Tensor コア GPUは、革新的なパフォーマンスとメモリ機能を備え、生成AIおよびHPCワークロードを強化します。HBM3eを搭載した初のGPUであるH200は、大容量かつ高速なメモリを提供し、科学コンピューティングによるHPCワークロードの推進と、生成AIや大規模言語モデル(LLM)の高速化を実現します。
製品の特長と利点
01
大容量で高速なメモリによる高いパフォーマンス
NVIDIA Hopperアーキテクチャを基盤とするNVIDIA H200は、毎秒4.8テラバイト(TB/s)の帯域幅を持つ141ギガバイト(GB)のHBM3eメモリを搭載した初のGPUです。これは、従来のNVIDIA H100 TensorコアGPUと比較して、約2倍のメモリ容量と1.4倍のメモリ帯域幅を実現します。H200は、生成AIや大規模言語モデル(LLM)の高速化を支援し、エネルギー効率の向上、総所有コストの削減、さらにHPCワークロードにおける科学計算の進化を加速します。
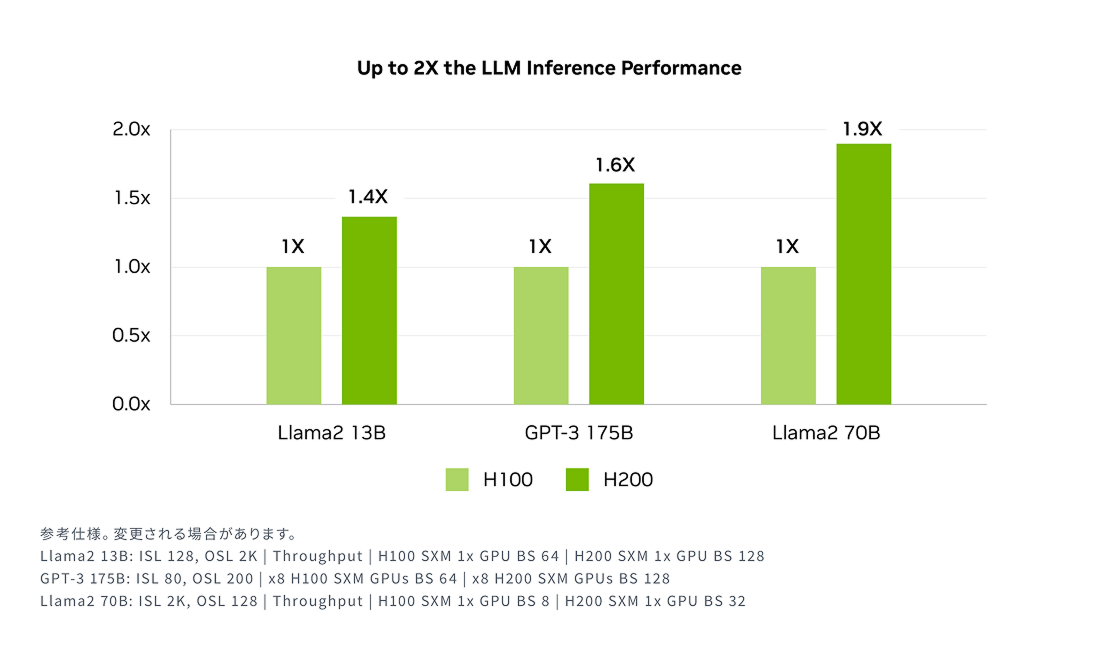
高性能なLLM推論で新たな価値を創出
進化を続けるAIの分野では、企業が多様な推論ニーズを満たすためにLLM(大規模言語モデル)を積極的に活用しています。特に、大規模なユーザーベースを対象としたAI推論の展開においては、総所有コスト(TCO)を抑えながら、最大限のスループットを実現する推論アクセラレータが求められます。
NVIDIA H200は、Llama 2のようなLLMを処理する際、従来のH100 GPUと比較して推論速度を最大2倍に向上させ、企業がより迅速に洞察を得られるよう支援します。
02
ハイパフォーマンスコンピューティングを加速
ハイパフォーマンス コンピューティング(HPC)アプリケーションにおいて、メモリ帯域幅は高速なデータ転送を可能にし、複雑な処理のボトルネックを解消する重要な要素です。シミュレーションや科学研究、人工知能といったメモリ集約型のHPCワークロードでは、NVIDIA H200の圧倒的なメモリ帯域幅がデータへのアクセスと操作を劇的に効率化します。これにより、CPUと比較して最大110倍の速さで結果を導き出すことが可能になります。
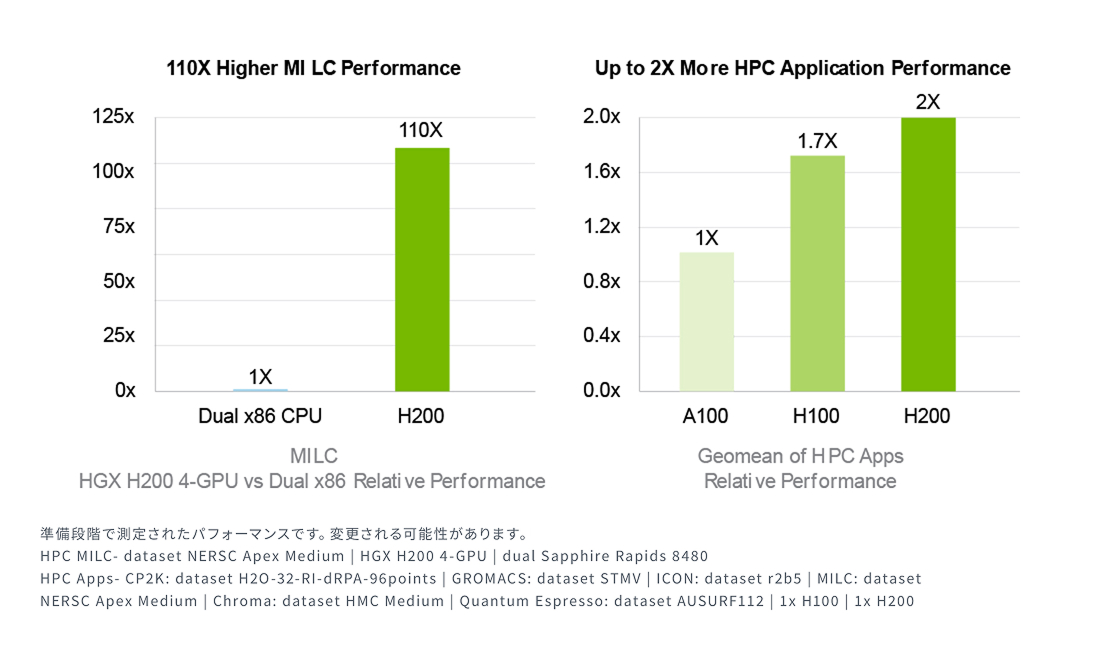
03
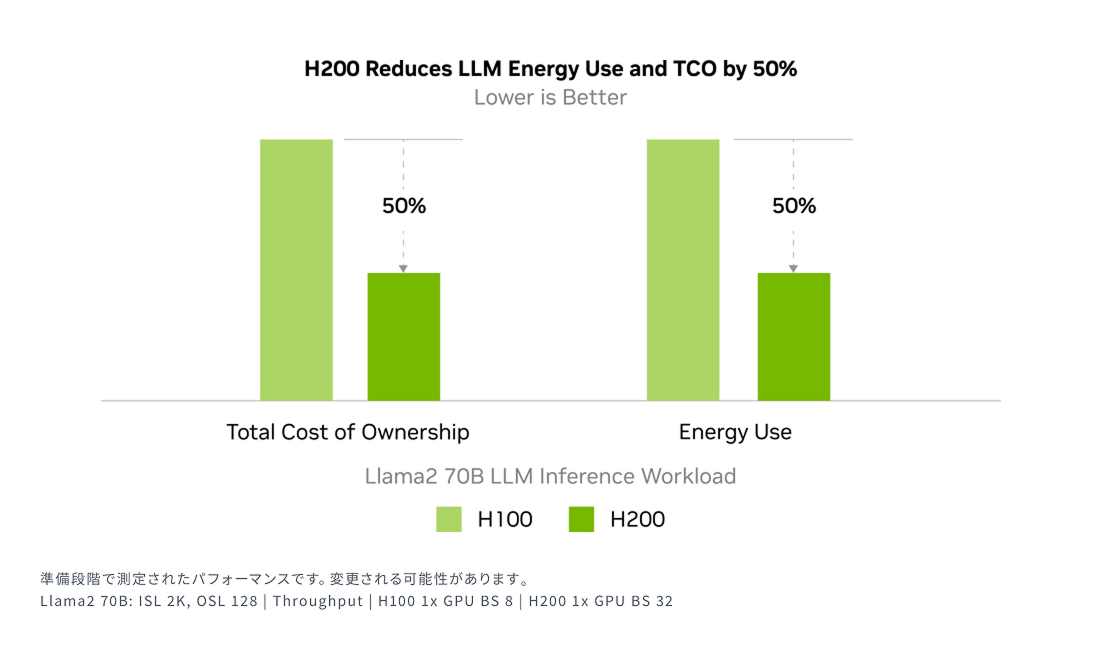
エネルギー効率とTCOを劇的に削減
NVIDIA H200 は、H100 Tensor コア GPU と同じ電力プロファイル内で、かつてないパフォーマンスを実現します。これにより、AIファクトリーやスーパーコンピューティング システムは、これまで以上に高速かつ環境に配慮した運用が可能となります。また、エネルギー効率の向上と運用コスト(TCO)の削減を通じて、AIや科学分野のコミュニティにとって経済的な優位性を提供します。
製品の活用例
研究機関・大学におけるAI開発
H200はHBM3eメモリにより大規模学習を高速化。大学や研究機関での画像認識・生成AI研究を効率的に推進します。
生成AI・LLM開発におけるディープラーニング活用
高帯域メモリとNVLinkでGPUを効率連携。H200は生成AIの学習や推論を高速化し、開発スピードとコストを改善します。
データセンターでの大規模運用
H200はHPCや解析処理を効率化。自動車・金融・医療など幅広い業界で研究から実運用までを支える基盤となります。
製品スペック
| フォーム ファクター | H200 SXM¹ | H200 NVL¹ |
|---|---|---|
| FP64 | 34 TFLOPS | 34 TFLOPS |
| FP64 Tensor コア | 67 TFLOPS | 67 TFLOPS |
| FP32 | 67 TFLOPS | 67 TFLOPS |
| TF32 Tensor コア | 989 TFLOPS² | 989 TFLOPS² |
| FP16 Tensor コア | 1,979 TFLOPS² | 1,979 TFLOPS² |
| FP8 Tensor コア | 3,958 TFLOPS² | 3,958 TFLOPS² |
| INT8 Tensor コア | 3,958 TFLOPS² | 3,958 TFLOPS² |
| GPU メモリ | 141GB | 141GB |
| GPU メモリ帯域幅 | 4.8TB/秒 | 4.8TB/秒 |
| デコーダー | 7 NVDEC 7 JPEG | 7 NVDEC 7 JPEG |
| コンフィデンシャル コンピューティング | サポート対象 | サポート対象 |
| 最大熱設計電力 (TDP) | 最大700W(構成可能) | 最大600W(構成可能) |
| マルチインスタンス GPU | 各18GBで最大7個のMIG | 各18GBで最大7個のMIG |
| フォーム ファクター | SXM | PCIe |
| 相互接続 | NVLink: 900GB/秒 PCIe Gen5: 128GB/秒 | 2ウェイまたは4ウェイの NVIDIA NVLink ブリッジ: 900GB/秒 PCIe Gen5: 128GB/秒 |
| サーバー オプション | GPUを4基または8基搭載のNVIDIA HGX H100 Partner および NVIDIA-Certified Systems™ | GPUを4基または8基搭載のNVIDIA HGX H200 パートナー製品および NVIDIA-Certified Systems™ |
| NVIDIA AI Enterprise | アドオン | 同梱 |
1.仕様は変更される場合があります。
2.疎性あり
製品のよくある質問
GPUサーバーはNVIDIA認定を受けていますか?
はい。NVIDIA認定済みのGPUサーバーを提供しています。
サーバーのサイジングに協力していただくことは可能ですか?
はい。用途や希望スペック、ご予算などをヒアリングさせていただき、最適なものを提案いたします。
スペックの細かなカスタマイズは可能ですか?
はい。ご希望があればCPU、メモリー、ストレージ、ネットワークなどを細かくカスタマイズ可能です。サーバー本体や搭載するGPUにより推奨構成があるため、まずはご希望をお伺いさせていただきながらご提案いたします。
価格について教えてください。
構成に応じてパーツが変わるため都度お見積りいたします。ご相談ください。
GPUDirect RDMAは利用できますか?
GPUDirect RDMAを利用可能なサーバーもございます。必要要件がありますのでまずはご希望などをお聞かせください。
H200導入までに要する期間はどれくらいですか?
ご導入までの期間は、構成内容や在庫状況、設置環境によって異なります。詳細なスケジュールは個別にご案内いたします。
NVIDIA H200 はどんな用途に向いていますか?
生成AI(LLM)、高精度推論、HPC、データ分析など、大規模モデル処理に特化しています。
H200 と H100 の主な違いは何ですか?
HBM3e 141GBによりメモリ帯域・容量が大幅向上し、LLM推論性能が強化されています。
LLM推論の速度はどれくらい向上しますか?
H100比で最大約1.4倍高速化し、70B〜200B級モデルの応答が大幅に改善します。
H200 が必要なケースと H100 で十分なケースの違いは何ですか?
大規模LLM処理や高速推論はH200向き。10〜30B級中心やコスト優先はH100でも十分です。
H200 搭載には専用サーバーが必要ですか?
はい。DGX/HGXベースのH200対応サーバーが必須で、一般的な筐体では搭載できません。
導入前に準備すべきことは何ですか?
モデルサイズ、必要性能、サーバー電源・冷却能力、予算、スケール方針を整理する必要があります。
推論用途のみでも H200 は導入価値がありますか?
あります。H200は推論性能が特に強化されており、商用推論基盤に最適です。
H200 と B100(Blackwell)の選択基準は何ですか?
すぐ導入ならH200、最高性能重視・予算に余裕ならB100が適しています。
パートナー

保証・サポート
導入時のサポート
HW選定のご相談から組み立て、ラッキングまでサポートいたします。 ご要望によりOS導入・初期設定・各種ソリューションの構築も対応可能です。 記載の無い要件であっても対応可能なケースがございます。








