

NVIDIA H100とは?その性能やおすすめの利用シーンを解説【トゥモロー・ネット テックブログ】

昨今においては、競うようにAIの開発が進んでおり、AIを用いた事業を展開する企業が増えています。
AIの開発に欠かせない装置が「GPU」であり、その一つがNVIDIAが発表した「H100」です。H100 Tensor Core GPU(以下H100と省略)は、前世代のA100と比べ約6倍もの処理能力を有しています。
とは言え、「NVIDIA H100にはどのような性能なのか」「おすすめの活用シーンを知りたい」と考えるご担当者もいるのではないでしょうか。
そこで今回は、NVIDIA H100の概要から性能、またAI開発との関係についてを詳しく解説します。今後、ビジネスシーンで活用をお考えのご担当者は、ぜひ参考にしてください。
目次
NVIDIA H100とは
NVIDIA H100とは、NVIDIA社によるイベント「GTC2022 Spring」で発表されたあらゆるワークロードに対応可能な高性能GPUです。
NVIDIA H100には、どのような特徴があるのでしょうか。
NVIDIA H100の特徴とは
H100の処理性能は、前世代であるA100の約6倍にのぼります。A100ではFP16(16ビット浮動小数点演算)での処理を行っていましたが、H100では、新たにFP8(8ビット浮動小数点演算)の採用により、「4000TFLOPS」という高い演算性能を実現しました。
またH100は、新しいアーキテクチャ「Hopper(ホッパー)」を採用しており、前世代の「Ampere」アーキテクチャのGPUに比べ、AI(人工知能)の学習や推論における演算処理性能を高めています。

NVIDIA H100の性能について
NVIDIA H100には、NVLinkとPCIeの2種類があります。ノード全体で GPU ごとに通信を高速化するNVIDIA® NVLink® Switch System では、最大で256個ものH100の接続が可能で、劇的な高速化を実現しています。
専用の「Transformer Engine」の利用により、兆単位の言語モデルにおけるパラメーターの実装が可能です。
ここでは、H100の性能について詳しく解説します。
最大30倍のAI推論性能
現代において、企業によるAIの導入は主流となりつつあり、新しい時代に向けて組織を加速させるためのエンドツーエンドの「AI対応インフラストラクチャ」を必要としています。
H100では、複合的な技術革新により前世代と比べ言語モデルが30倍も高速化され「対話型AI」を可能としています。
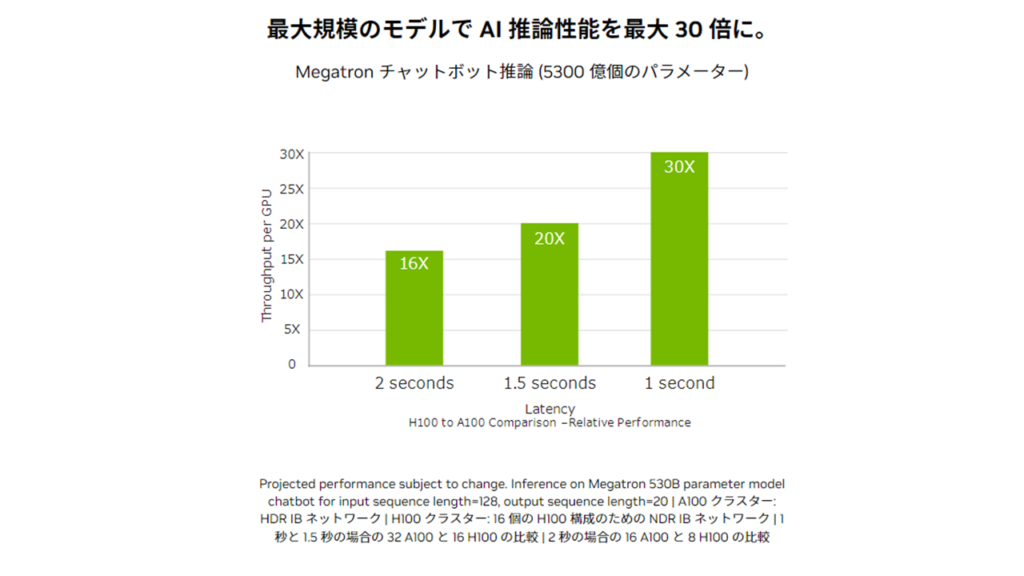
引用:NVIDIA|NVIDIA H100 Tensor コア GPU
また、DRAMはHBM2、メモリインターフェイスは6,144bit、トランジスタ数は540億とVoltaの2倍以上を誇り、メモリ容量は40GBを実現しています。
NVIDIA H100 SXMとH100 PCIeの違い
NVIDIA H100には、PCIe版とSXM版の2種類があります。
PCIe版は、一般的なコンピュータのPCI Expressスロットに挿入して使用するタイプで、既存のデバイスに導入しやすく汎用性が高いのが特徴です。また、専用のNVLinkブリッジを用いることで、連結したGPU間で高速な処理を実現できます。
一方、SXM版は基本的に8枚セットの専用サーバーとして提供され、NVLinkを活用して複数のGPUを効率的に連結することで、より高い処理速度を発揮します。画像では、SXM版の金色部分に8枚のGPUが連結されている様子が確認できます。
スペック表
| NVIDIA H100 SXM5 | NVIDIA H100 PCIe | |
| GPUダイコードネーム | GH100 | GH100 |
| フォームファクター | SXM5 | PCIe Gen 5 |
| GPUアーキテクチャ | NVIDIA Hopper | NVIDIA Hopper |
| TPC | 66 | 57 |
| SM | 132 | 114 |
| FP32コア/GPU | 16,896 | 14,592 |
| FP32コア/SM | 128 | 128 |
| FP64コア/GPU(Tensorを含めない) | 8,448 | 7,296 |
| FP64コア/SM (Tensorを含めない) | 64 | 64 |
| INT32コア/GPU | 8,448 | 7,296 |
| INT32コア/SM | 64 | 64 |
| Tensorコア/GPU | 528 | 456 |
| Tensorコア/SM | 4 | 4 |
| GPUブースト時クロック | 調整中 | 調整中 |
| 最大TF32 Tensor TFLOPS※1 | 500/1,000*2 | 400/800*2 |
| 最大FP64 Tensor TFLOPS※1 | 60 | 48 |
| 最大FP8 Tensor TFLOPS FP16 Accumulate有効時※1 | 2,000/4,000*2 | 1600/3200*2 |
| 最大FP8 Tensor TFLOPS FP32 Accumulate有効時※1 | 2,000/4,000*2 | 1600/3200*2 |
| 最大FP16 Tensor TFLOPS FP16 Accumulate有効時※1 | 1,000/2,000*2 | 800/1600*2 |
| 最大FP16 Tensor TFLOPS FP32 Accumulate有効時※1 | 1,000/2,000*2 | 800/1600*2 |
| 最大INT8 Tensor TOPS※1 | 2,000/4,000*2 | 1,600/3,200*2 |
| 最大INT32 TOPS※1 | 30 | 24 |
| 最大BF16 TFLOPS (Tensor未使用時)※1 | 120 | 96 |
| 最大FP16 TFLOPS (Tensor未使用時)※1 | 120 | 96 |
| 最大FP32 TFLOPS (Tensor未使用時)※1 | 60 | 48 |
| 最大FP64 TFLOPS (Tensor未使用時)※1 | 30 | 24 |
| メモリ容量 | 80GB | 80GB |
| メモリインターフェース | HBM3(5120-bit) | HBM2e(5120-bit) |
| メモリ帯域幅 | 3,000GB/s | 2,000GB/s |
| メモリデータレート | 調整中 | 調整中 |
| シェアードメモリサイズ/SM | 最大228KBに設定可能 | 最大228 KBに設定可能 |
| テクスチャユニット | 528 | 456 |
| L2キャッシュ(ダイ全体) | 50MB | 50MB |
| レジスタファイルサイズ/GPU | 33,792KB | 29,184KB |
| レジスタファイルサイズ/SM | 256KB | 256KB |
| TDP*1 | 700W | 350W |
※2:スパース性を利用した場合です。
NVIDIA H100のDGXとHGXの違い
NVIDIAのH100には、DGX H100とHGX H100の2種類があります。どちらも同じNVIDIA純正のH100 GPU(SXM版)を8枚搭載していますが、提供形態とカスタマイズの柔軟性に違いがあります。
DGX H100は、GPU開発元であるNVIDIA自身が組み立てて提供する純正サーバーです。
一方、HGX H100はNVIDIAのパートナー企業がH100 GPUを用いて組み立てたサーバーです。
性能面では両者に大きな差はなく、いずれもGPU間通信にNVLink・NVSwitchを利用し、GPUメモリは合計640GB、vCPUは112コア、システムメモリは2TBを搭載しています。ストレージ容量はDGX H100が34.56TB、HGX H100が30TBとなっており、細かい構成の違いはありますが、基本的な性能は同等です。
| 項目 | DGX H100 | HGX H100 |
| 提供形態 | NVIDIAが自社で組み立て・提供する純正サーバー | NVIDIAパートナー企業が組み立てて提供 |
| 製造主体 | NVIDIA | NVIDIA認定パートナー企業 |
| 搭載GPU | H100(SXM版)×8基 | H100(SXM版)×8基 |
| GPU間通信 | NVLink・NVSwitch | NVLink・NVSwitch |
| GPUメモリ合計 | 640GB | 640GB |
| vCPU | 112コア | 112コア |
| システムメモリ | 2TB | 2TB |
| ストレージ容量 | 34.56TB | 30TB |
| カスタマイズ性 | NVIDIA標準構成(最適化済み) | ベンダーごとに構成変更が可能 |
| 性能差 | 基本性能は同等 | 基本性能は同等 |
NVIDIA H100のおすすめの活用シーン

H100は高性能GPUとして多彩な用途で活用が可能です。
生成AI・大規模言語モデル(LLM)
大規模データのトレーニングや推論、LLM作成の高速化に最適です。H100によって、効率的なモデル学習・レスポンス性能向上が期待できます。
HPC(ハイパフォーマンスコンピューティング)
科学計算・気象シミュレーション・数値解析など、高並列処理が求められる用途に向いています。
医療・金融・研究データ処理
機密性の高いデータ処理に対応するコンフィデンシャルコンピューティング機能も備えています。
以下では、GPUとAIとの関係について見ていきます。
AI開発とGPUの関係
AI開発においてGPUが活用される理由として、並列計算能力の高さが挙げられます。
GPUとは(Graphics Processing Unit)の略語であり、本来は画像処理を行うものを意味しています。元々GPUは、パソコンのグラフィックボードなどに使用されていました。
AIは、多大なる演算処理が必要な技術であるため、高速処理が可能なチップを必要とします。CPUほど複雑で多くの処理はできないGPUですが、並列処理を得意としているので、似たような計算を高速でくり返すことが可能です。
GPUが用いられるAI分野とは
AIの開発において利用されているGPUですが、具体的にどのようなAIの分野で用いられているのでしょうか。
例えばディープラーニングは、ニューラルネットワークという「人の神経細胞の仕組み」へ着目した計算モデルをベースとした技術です。
ディープラーニングの基本的な仕組みは、データ出力を行う出力層とデータの入力を行う入力層の間に、データの特徴量の抽出や保持をする中間層を配置します。さらに、それぞれの層が連結することで難解な判断を可能とするものです。
行列計算を主としたディープラーニングには、並列計算能力が高いGPUが向いているため、画像処理に限らず言語処理や音声処理にもGPUが使用されています。
その計算能力をさらに幅広く活用できるようにした「GPGPU(General Purpose Computing on GPU)」があります。GPGPUは、画像処理のほか、高い並列計算能力を必要とされる分野で活用されています。
NVIDIA GPUはなぜAIに最適なのか?選定するポイントも紹介
H100に関するよくある質問
ここではGPUH100に関するよくある質問をご紹介します。
DGX H100とHGX H100のどちらを選ぶべきですか?
短期間で導入したい、NVIDIA純正の最適化済み構成をそのまま使いたい場合はDGX H100が向いています。一方で、CPU構成やストレージ、ネットワークなどを自社要件に合わせて柔軟に設計したい場合はHGX H100が適しています。
生成AIやLLM開発にはDGXとHGXどちらが向いていますか?
どちらも大規模言語モデル(LLM)や生成AIの学習・推論に対応可能です。既製パッケージで迅速に導入するならDGX、ネットワーク設計やストレージ拡張を含めて最適化したい場合はHGXが適しています。
まとめ
NVIDIA H100の処理性能は、前世代であるA100の約6倍にのぼります。新たにFP8(8ビット浮動小数点演算)を採用したことで、高い演算性能を実現しています。
その高い演算性能からAI開発にも活用され、ディープラーニングなどのAI分野で利用されています。
トゥモロー・ネットでご支援できること
トゥモロー・ネットでは、NVIDIAのパートナーとしてH100をはじめとするGPU製品の販売や導入サポートを実施しています。きめ細やかな提案、構築、導入を提供いたしますので、GPUをお探しの方はぜひお問合せください。
お問合せ先
関連ページ
GPUサーバーとは?導入メリット、用途、選び方から最新機種まで
この記事を書いた人

株式会社トゥモロー・ネット
トゥモロー・ネットは「ITをもとに楽しい未来へつなごう」という経営理念のもと、感動や喜びのある、より良い社会へと導く企業を目指し、最先端のテクノロジーとサステナブルなインフラを提供しています。設立以来培ってきたハードウェア・ソフトウェア製造・販売、運用、保守などインフラに関わる豊富な実績と近年注力するAIサービスのコンサルティング、開発、運用、サポートにより、国内システムインテグレーション市場においてユニークなポジションを確立しています。
インフラからAIサービスまで包括的に提供することで、システム全体の柔軟性、ユーザビリティ、コストの最適化、パフォーマンス向上など、お客様の細かなニーズに沿った提案を行っています。