

Docker×SlurmでGPUを最大活用!ローカルLLM効率化を検証【トゥモロー・ネット 技術ブログ】

ローカルLLMを効率よく運用するには、GPUリソースを無駄なく管理できる仕組みが不可欠です。
今回は、ジョブスケジューラ「Slurm」とコンテナ基盤「Docker」を組み合わせ、GPUを効率的に割り当てるローカルLLM環境の構築を検証してみました。
目次
Slurmとは?GPUジョブ管理を効率化
Slurmはジョブスケジューラ兼リソースマネージャでLinux OSで動作するオープンソースソフトウェアです。ユーザがジョブを投入すると、Slurmによって各ジョブにサーバリソース(CPU、メモリ、GPU)が排他的、効率的に割り当てられます。
また、ジョブはリソースの数だけ並列実行することができ、サーバリソースが枯渇した場合はジョブがキュー待ち状態になります。多くのユーザが同時にジョブを実行するシステムではSlurmを導入することによってリソースを効率的に使用することができます。
検証構成
本検証では下記の図のようにSupermicro製GPUサーバにNVIDIA RTX 6000 Adaを2枚入れます。OSとしてUbuntu Server 24.04.3 LTSをインストールし、その上にSlurm関連デーモン(slurmctld、slurmd、munged、slurmdbd)とRootless Docker、ジョブ履歴保存用データベースとしてmariadbを構築します。
ユーザーがSlurmジョブスクリプトを実行すると管理デーモンslurmctldが計算デーモンslurmdにジョブを割り当てます。slurmdはDocker上でコンテナを起動するように命令し、コンテナにサーバリソース(CPU、メモリ、GPU)を割り当てます。コンテナ上で実際のジョブ計算が行われ、計算終了後にコンテナが停止します。本検証では複数ジョブ同時投入時にGPUがどのようにコンテナに割り当てられるか検証します。
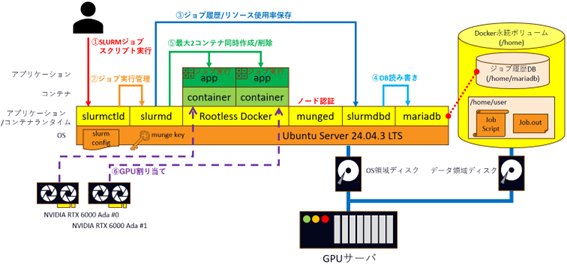
Slurm環境構築
Ubuntu Server 24.04.3 LTSにmariadb、Rootless Docker、python3、NVIDIA Driver、NVIDIA Container Toolkitをインストールした状態で、下記コマンドでSlurmを構築します。
wget https://download.schedmd.com/slurm/slurm-25.05.0.tar.bz2
tar -jxvf /root/slurm-25.05.0.tar.bz2
cd /root/slurm-25.05.0
MYSQL_CONFIG=/usr/bin/mysql_config ./configure –enable-cgroupv2
make
make install
Docker+SlurmでGPU2枚を使用できるように設定ファイルを編集します。
- /usr/local/etc/slurm.conf
…(省略)…
AccountingStorageTRES=gres/gpu
…(省略)…
PartitionName=p1 Nodes=ALL Default=YES MaxTime=INFINITE State=UP OverSubscribe=YES
NodeName=gpuserver CPUs=48 RealMemory=257619 Sockets=2 CoresPerSocket=12 ThreadsPerCore=2 Gres=gpu:2 Port=6818 State=UNKNOWN - /usr/local/etc/gres.conf
NodeName=gpuserver Name=gpu File=/dev/nvidia0
NodeName=gpuserver Name=gpu File=/dev/nvidia1 - /etc/nvidia-container-runtime/config.toml
…(省略)…
no-cgroups = true
…(省略)…
Slurmジョブスクリプト
SlurmジョブスクリプトではSBATCHオプションでジョブに割り当てるサーバリソースを指定することができます。今回はジョブにCPU:2threads、メモリ:2GB、GPU:1枚を割り当て、Whisperコンテナ(OpenAI社開発の自動音声認識システム)を起動し、音声データをテキストに変換します。
- run-container-openai-whisper.sh
!/bin/bash
SBATCH -p p1
SBATCH –job-name openai-whisper
SBATCH –nodes=1
SBATCH –tasks-per-node=1
SBATCH –ntasks=1
SBATCH –cpus-per-task=2 #CPUスレッド割り当て数
SBATCH –mem=2G #メモリ割り当て量
SBATCH –gres=gpu:1 #GPU割り当て枚数
SBATCH -o openai-whisper.out
SBATCH -e openai-whisper.err
SBATCH –account=user1
Get UUID of GPUs
GPU_LIST=nvidia-smi -L | awk -F'[()]' '{print $2}'|cut -c 7-| paste -sd ','
Run OpenAI whisper Container
srun –job-name=Run_OpenAI_whisper bash -c “docker run –rm –gpus ‘\”device=$GPU_LIST\”‘ -v /home/user1:/home/user1 –cgroupns=host -v /sys/fs/cgroup:/sys/fs/cgroup:rw openai-whisper:latest sh /home/user1/job-openai-whisper.sh” - job-openai-whisper.sh
Execute OpenAI whisper
whisper –model turbo –device cuda –language Japanese –model_dir /home/user1/openai-whisper /home/user1/Gmjrwl_D72E.wav
検証結果
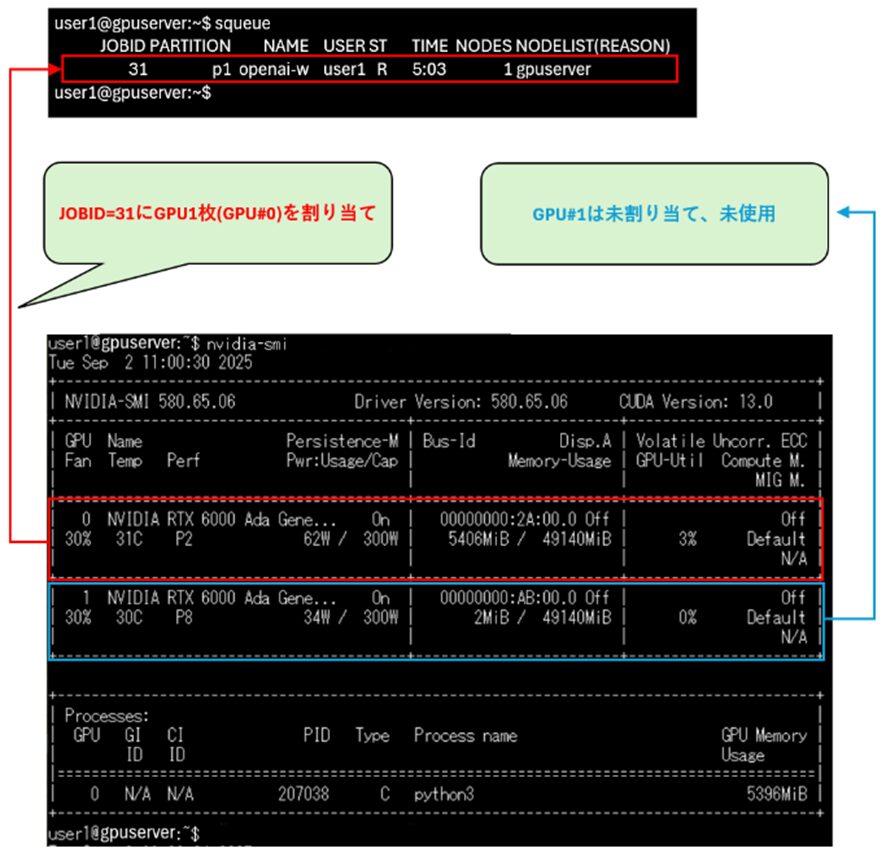
Slurmジョブスクリプトを複数投入(sbatch run-container-openai-whisper.sh)し、GPUがどのようにジョブに割り当てられるか検証しました。実行中、キュー待ちのジョブはsqueueコマンドで確認しました。
1ジョブ投入
1つのジョブ投入した場合、2つのGPUのうち、1つのGPUのメモリ使用率(nvidia-smiコマンドで確認)が上昇します。このことからSlurmによって、ジョブ1つにGPU1枚が割り当てられ、計算が行われていることが分かります。
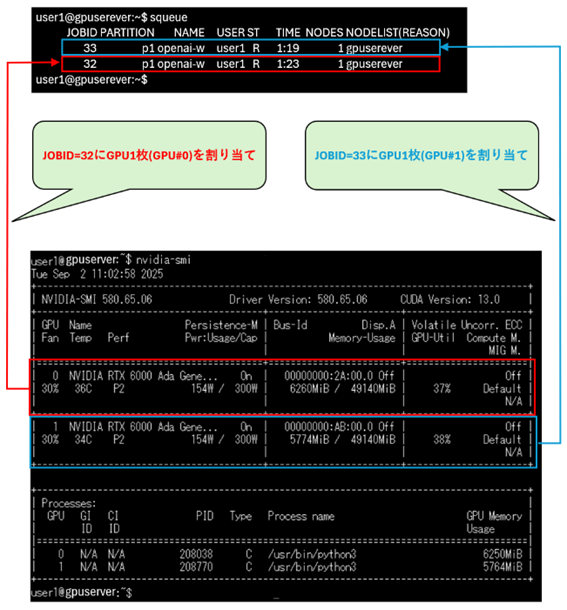
2ジョブ同時投入
2つのジョブ同時投入した場合、2つのGPUのメモリ使用率が上昇します。このことからSlurmによって、ジョブ2つにGPUが1枚ずつ割り当てられていることが分かります。
4ジョブ同時投入
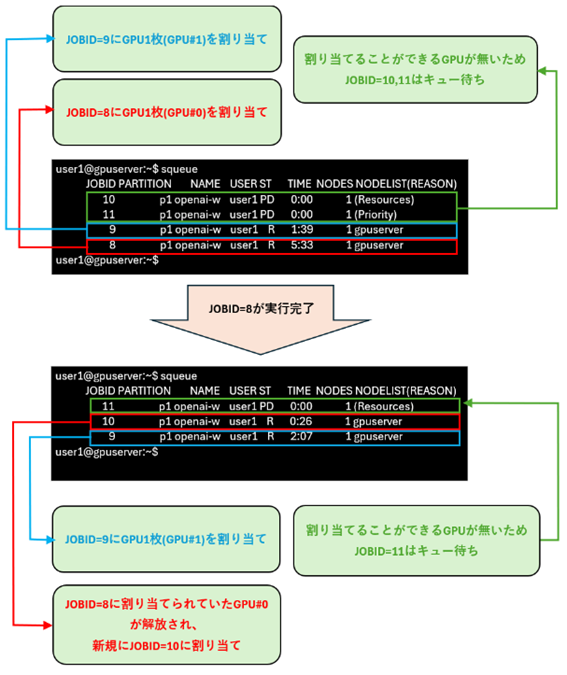
4つのジョブ同時投入した場合、1つ目と2つ目のジョブ(JOBID=8、9)にはGPUが1枚ずつ割り当てられます。残りのジョブ(JOBID=10、11)には割り当てられるGPUがないため、ジョブはキュー待ちになります。1つ目のジョブ(JOBID=8)が実行完了するとGPU1枚が解放され、3つ目のジョブ(JOBID=10)に割り当てられます。このことからSlurmはリソースの数だけジョブを並列処理し、ジョブが完了してリソースが解放されたのと同時にキュー待ちのジョブにリソースを再割り当てすることが分かります。
まとめ
今回の検証結果によって、Slurmが排他的、効率的にリソースをジョブに割り当てることが確認できました。
LLMでは多くのユーザが同時にアクセスし、GPUを効率的に使うことが重要視されているため、AI開発環境での分散処理を最適化するにはSlurmの導入は最適解になります。トゥモロー・ネットでは効率的なLLMアプリケーションのアーキテクチャをご提案できますので興味があればぜひお問い合わせください。
お問合せ先

関連記事はこちら
ローカルLLMとRAGを構築してみた【ローカルAI基盤】
人事担当が社内チャットボットの構築を手伝ってみた
初心者がRocky LinuxでCephFSを構築!AIツールとの試行錯誤の軌跡
この記事を書いた人

株式会社トゥモロー・ネット
トゥモロー・ネットは「ITをもとに楽しい未来へつなごう」という経営理念のもと、感動や喜びのある、より良い社会へと導く企業を目指し、最先端のテクノロジーとサステナブルなインフラを提供しています。設立以来培ってきたハードウェア・ソフトウェア製造・販売、運用、保守などインフラに関わる豊富な実績と近年注力するAIサービスのコンサルティング、開発、運用、サポートにより、国内システムインテグレーション市場においてユニークなポジションを確立しています。
インフラからAIサービスまで包括的に提供することで、システム全体の柔軟性、ユーザビリティ、コストの最適化、パフォーマンス向上など、お客様の細かなニーズに沿った提案を行っています。