

Hammerspace Anvilによる未使用NVMeの有効利用【トゥモロー・ネット 技術ブログ】

目次
はじめに
データセンターでは多くのGPUサーバーに搭載されたNVMeが有効活用されていないケースが少なくありません。Hammerspace Anvilサーバーを利用すると、これらの未使用NVMeを束ねて冗長化NASを構築できます。
本記事では、Hammerspace Anvilのインストール方法とNAS冗長化方法を解説いたします。
Hammerspaceとは
Hammerspace(HS)は、分散したオンプレミス、クラウド、エッジストレージを統合し、保存場所を意識せずにどこからでもデータを利用できるようにするソフトウェアデータプラットフォームです。
HSでは分散データの分布を最適化し、冗長化、アクセス高速化を実現するためにデータの移動・配置を自動的に行います。
GPUサーバーではデータへの高速アクセスが求められます。Hammerspace AnvilではGPUサーバに搭載された未使用のローカルNVMe(Tier0)を冗長化NASとして活用することができ、GPU-データ間の高速アクセスを可能にします。
検証構成
本検証では下記の図のようにSupermicro製GPUサーバ(AS -1114S-WN10RT) x2にそれぞれNVMe x4、NVIDIA H200 NVL 141GBを搭載します。NVMe x4でRAIDデバイスを構成しており、OSはUbuntu 22.04です。
Proxmox VEには仮想マシンとして、Hammerspace AnvilとNFS Client(Ubuntu 24.04)を作成しています。Hammerspace AnvilがGPUサーバーのRAIDデバイス間を冗長化・NFS共有(Hammerspace Share、HS Share)し、それをNFS Clientにマウントします。
本検証ではNFS ClientからHS Shareに書き込みを行い、RAIDデバイスにミラーリングされてデータが保存されることを確認します。
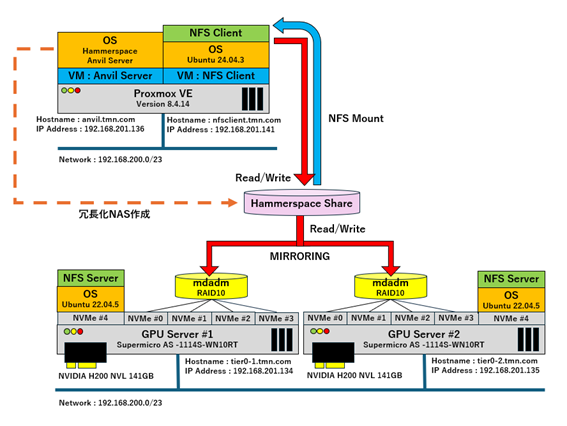
検証環境構築手順
1.Hammerspace Anvilのインストール
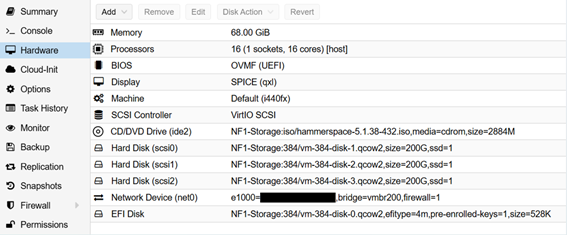
Proxmox VEに下記スペックで仮想マシンを作成します。
「CD/DVD Drive」にHSインストールISOを指定します。(HSインストールISOの入手方法は弊社にお問い合わせください)
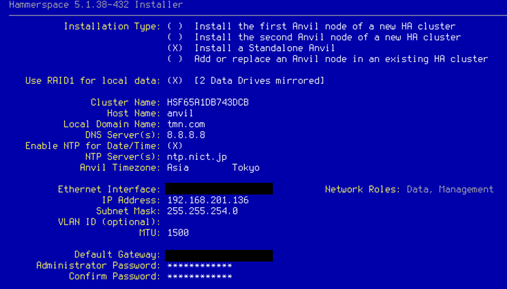
HSのインストールISOをブートし、以下の設定値でHammerspace Anvilをインストールします。
2.GPUサーバーのRAIDデバイス作成
以下の手順でNVMe RAIDデバイスを作成していきます。
① NVMe x4のRAIDデバイス(RAID10)を作成します。
mdadm –create –verbose /dev/md0 –level=10 –raid-devices=4 /dev/nvme0n1 /dev/nvme1n1 /dev/nvme2n1 /dev/nvme3n1
mdadm –detail –scan >> /etc/mdadm/mdadm.conf
update-initramfs -u
mkfs.ext4 /dev/md0
mkdir /nfs-vol
mount /dev/md0 /nfs-vol
echo “UUID=$(blkid -s UUID -o value /dev/md0) /nfs-vol ext4 defaults,nofail 0 2” >> /etc/fstab
② NFSサーバをインストールします。
apt install nfs-server -y
systemctl enable –now nfs-server
③ RAIDデバイスをHammerspace AnvilへNFS共有します。(赤文字部分はHammerspace AnvilのData IP Addressを指定します。)
echo “/nfs-vol 192.168.201.136(rw,no_root_squash,sync,secure,mp,no_subtree_check)” >> /etc/exports
④ RAIDデバイスをNFS ClientへNFS共有します。(赤文字部分はNFS ClientのDataネットワークを指定します。)
echo “/nfs-vol 192.168.200.0/23(rw,root_squash,sync,secure,mp,no_subtree_check)” >> /etc/exports
exportfs -r
以下の手順でHS Shareを作成し、GPUサーバーのRAIDデバイス間を冗長化させます。
① ブラウザでHammerspace AnvilのWeb Interface(https://192.168.201.136)にアクセスし、adminユーザでログインします。
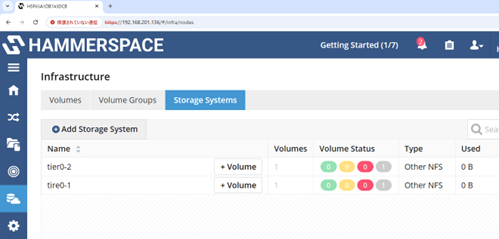
② 「Infrastructure」-「Storage Systems」メニューで「Add Storage System」をクリックし、GPUサーバ x2をAnvilに登録します。(登録する際に「Name」はtier0-1およびtier0-2、「Storage Type」はNAS Storage、「Type」はOther NFSを選択します。)
③ 「Infrastructure」-「Volumes」メニューで「Add Volumes」をクリックし、GPUサーバーのRAIDデバイスをHammerspace Anvil に登録します。
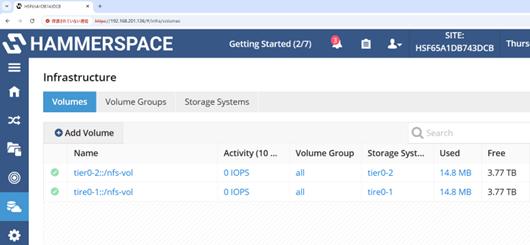
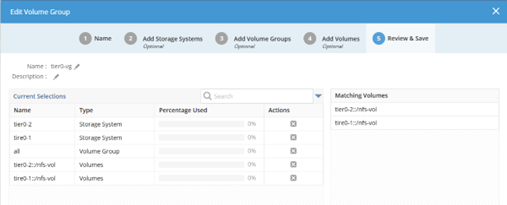
④ 「Infrastructure」-「Volume Groups」メニューで「Create Volume Group」をクリックし、GPUサーバー x2でVolume Groupを作成します。
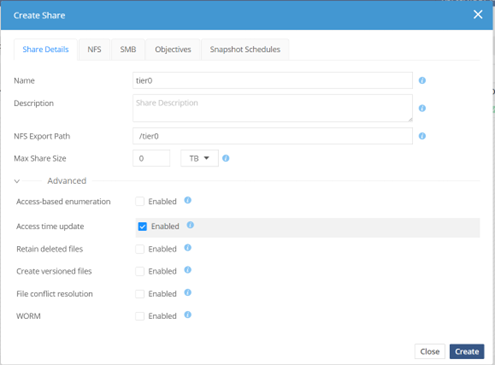
⑤ 「Data」-「share」メニューで「Create Share」をクリックし、GPUサーバー x2でVolume Groupを作成します。
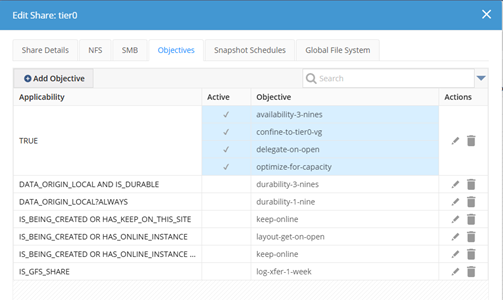
Objectivesは下記のように設定します。
検証結果
NFS ClientからHS Shareに書き込みを行います。NFS ClientにHS ShareをNFSマウントします。赤文字のIPアドレスはHammerspace AnvilのData IP Addressを指定します。HS Shareに何もファイルがない状態で以下のコマンドで10GBのファイル10GB.fileを作成します。
mkdir /mnt/tier0
mount -o vers=4.2 192.168.201.136:/tier0 /mnt/tier0
dd if=/dev/random of=/mnt/tier0/10GB.file bs=1M count=10240
HS Web InterfaceでHS Share=tier0のFilesを確認すると、10GB.fileのOn Volumes(ファイル保存場所)が2Volumes(GPUサーバーのRAIDデバイス x2)になっていることが確認できます。
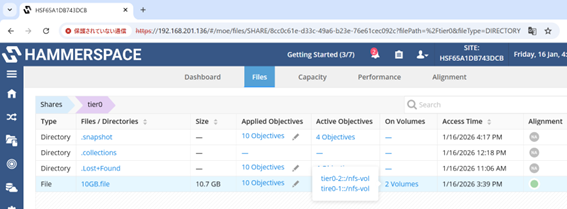
また、Volumesを確認するとGPUサーバーのRAIDデバイス x2のUsedが10GB.fileのサイズと等しくなっています。
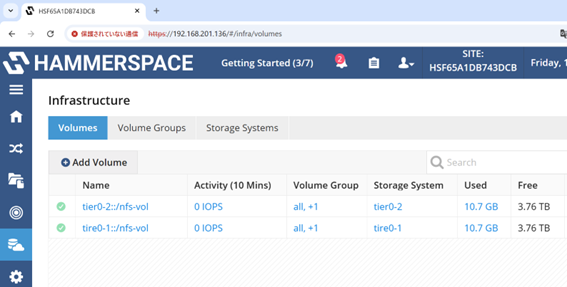
これは10GB.fileが2つのGPUサーバのRAIDデバイスにミラーリングされて保存されていることを表しています。このことからHammerspace Anvil がGPUサーバー間でデータを冗長化することが分かりました。
まとめ
今回の検証結果によって、Hammerspace Anvilサーバを導入するとGPUサーバー間でデータをミラーリングできることが分かりました。 GPU環境におけるストレージ性能向上や、未使用NVMeの活用、管理を行う場合はHammerspace Anvil 導入は有力な選択肢です。
トゥモロー・ネットではHammerspaceをご提案できますので興味があればぜひお問い合わせください。
お問合せ先

関連記事はこちら
Hammerspace Data Platform
Docker×SlurmでGPUを最大活用!ローカルLLM効率化を検証
今更聞けないPacemakerとCorosyncによるHAクラスタ構成
この記事を書いた人

株式会社トゥモロー・ネット
トゥモロー・ネットは「ITをもとに楽しい未来へつなごう」という経営理念のもと、感動や喜びのある、より良い社会へと導く企業を目指し、最先端のテクノロジーとサステナブルなインフラを提供しています。設立以来培ってきたハードウェア・ソフトウェア製造・販売、運用、保守などインフラに関わる豊富な実績と近年注力するAIサービスのコンサルティング、開発、運用、サポートにより、国内システムインテグレーション市場においてユニークなポジションを確立しています。
インフラからAIサービスまで包括的に提供することで、システム全体の柔軟性、ユーザビリティ、コストの最適化、パフォーマンス向上など、お客様の細かなニーズに沿った提案を行っています。